常用函数
str
- string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数
- string.find(str, beg=0, end=len(string)) 检测str是否包含在string中,如果beg和end指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1
- string.format()
1
2
3
4
5
6
7
8
| >>>"{} {}".format("hello", "world")
'hello world'
>>> "{0} {1}".format("hello", "world")
'hello world'
>>> "{1} {0} {1}".format("hello", "world")
'world hello world'
|
也可以设置参数
1
2
3
4
5
6
7
8
9
| print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list))
|
也可以向 str.format() 传入对象:
1
2
3
4
5
| class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value))
|
格式化数字的方法
d means expecting an int:
1
2
| >>> "{:d}".format(3)
'3'
|
2d means formats to 2 characters using padding (whitespace by default)
1
2
| >>> "{:2d}".format(3)
' 3'
|
0> means using 0 as padding, and right adjust the result:
1
2
| >>> "{:0>2d}".format(3)
'03'
|
- string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
- string.replace(str1, str2, num=string.count(str1)) 把string中str1替换为str2,如果num指定,则替换不超过num次
- string.split(str=””, num=string.count(str)) 以 str 为分隔符切片 string为列表,如果 num 有指定值,则仅分隔 num+1 个子字符串
- string.strip([obj]) 在 string 上执行 lstrip()和 rstrip()
列表
- list(seq) 将元组转换成列表
- list.append() 在列表末尾添加新的对象
- list.count() 统计某个元素在列表中出现的次数
- list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
元组
tuple(iterable) 将可迭代系列转换为元组。
1
2
3
4
| >>> list1= ['Google', 'Taobao', 'Runoob', 'Baidu']
>>> tuple1=tuple(list1)
>>> tuple1
('Google', 'Taobao', 'Runoob', 'Baidu')
|
元组不变是指 元组所指向的内存中的内容不可变。
1
2
3
4
5
6
7
8
9
10
| >>> tup = ('r', 'u', 'n', 'o', 'o', 'b')
>>> tup[0] = 'g'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> id(tup)
4440687904
>>> tup = (1,2,3)
>>> id(tup)
4441088800
|
字典
1
2
3
4
5
6
7
8
9
| d={1:"a",2:"b",3:"c"}
result=[]
for k,v in d.items():
result.append(k)
result.append(v)
print(result)
>> [1, 'a', 2, 'b', 3, 'c']
|
集合
集合运算
1
2
3
4
5
6
7
8
9
10
| data_1 = {'Mathematics', 'Chinese', 'English', 'Physics', 'Chemistry', 'Biology'}
data_2 = {'Mathematics', 'Chinese', 'English', 'Politics', 'Geography', 'History'}
data_1 & data_2
data_1 | data_2
data_1 - data_2
data_1 ^ data_2
|
sorted()
如果你需要对可迭代对象进行排序,比如列表、元组、字典,首先以列表为例子,可以直接使用内置函数sorted完成任务
1
2
3
4
5
6
| data = [-1, -10, 0, 9, 5]
new_data = sorted(data)
print(new_data)
|
对元组使用之后输出类型会变成列表
1
2
3
4
5
| data = (-1, -10, 0, 9, 5)
new_data = sorted(data, reverse=True)
print(new_data)
>>> [9, 5, 0, -1, -10]
|
字典
1
2
3
4
5
6
7
8
9
| data = [
{"name" : "jia", "age" : 18},
{"name" : "yi", "age" : 60},
{"name" : "bing", "age" : 20}
]
new_data = sorted(data, key=lambda x: x["age"])
print(new_data)
>>> [{'name': 'jia', 'age': 18}, {'name': 'bing', 'age': 20}, {'name': 'yi', 'age': 60}]
|
pandas
get_dummies()
pandas实现one hot encode的方式
1
| pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)[source]
|
例子
1
2
3
4
5
6
7
8
| import pandas as pd
df = pd.DataFrame([
['green', 'A'],
['red', 'B'],
['blue', 'A']
])
df.columns = ['color', 'class']
df = pd.get_dummies(df)
|
get_dummies前
|
color |
class |
| 0 |
green |
A |
| 1 |
red |
B |
| 2 |
blue |
A |
get_dummies后
|
color_blue |
color_green |
color_red |
color_A |
color_B |
| 0 |
0 |
1 |
0 |
1 |
0 |
| 1 |
0 |
0 |
1 |
0 |
1 |
| 2 |
1 |
0 |
0 |
1 |
0 |
可以对指定列进行get_dummies
1
| pd.get_dummies(df.color)
|
|
blue |
green |
red |
| 0 |
0 |
1 |
0 |
| 1 |
0 |
0 |
1 |
| 2 |
1 |
0 |
0 |
将指定列进行get_dummies 后合并到元数据中
1
| df = df.join(pd.get_dummies(df.color))
|
|
color |
class |
blue |
green |
red |
| 0 |
green |
A |
0 |
1 |
0 |
| 1 |
red |
B |
0 |
0 |
1 |
| 2 |
blue |
A |
1 |
0 |
0 |
concat()
连接内容 objs
需要连接的数据,可以是多个 DataFrame 或者 Series。必传参数。
1
2
3
4
5
6
7
8
9
| # Series 或 DataFrame 对象的序列或映射
s1 = pd.Series(['a', 'b'])
s2 = pd.Series(['c', 'd'])
pd.concat([s1, s2])
# df
df1 = pd.DataFrame([['a', 1], ['b', 2]], columns=['letter', 'number'])
df2 = pd.DataFrame([['c', 3], ['d', 4]], columns=['letter', 'number'])
pd.concat([df1, df2])
|
轴方向 axis
连接轴的方法,默认是 0,按行连接,追加在行后边,为 1 时追加到列后边。
1
2
| # {0/’index’, 1/’columns’}, default 0
pd.concat([df1, df4], axis=1) # 按列
|
合并方式 join
其他轴上的数据是按交集(inner)还是并集(outer)进行合并。
1
2
| # {‘inner’, ‘outer’}, default ‘outer’
pd.concat([df1, df3], join="inner") # 按交集
|
保留索引 ignore_index
是否保留原表索引,默认保留,为 True 会自动增加自然索引。
1
2
| # bool, default False
pd.concat([df1, df3], ignore_index=True) # 不保留索引
|
dropna()
DataFrame.dropna(axis=0, how=’any’, thresh=None, subset=None, inplace=False)
axis:
- axis=0: 删除包含缺失值的行
- axis=1: 删除包含缺失值的列
how: 与axis配合使用
- how=‘any’ :只要有缺失值出现,就删除该行货列
- how=‘all’: 所有的值都缺失,才删除行或列
thresh: axis中至少有thresh个非缺失值,否则删除
比如 axis=0,thresh=10:标识如果该行中非缺失值的数量小于10,将删除改行
subset: list
在哪些列中查看是否有缺失值
inplace: 是否在原数据上操作。如果为真,返回None否则返回新的copy,去掉了缺失值
drop()
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=’raise’)
- labels: 要删除行或列的列表
- axis: 0 行 ;1 列
fillna()
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
value: scalar, dict, Series, or DataFrame
dict 可以指定每一行或列用什么值填充
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
在列上操作
- ffill / pad: 使用前一个值来填充缺失值
- backfill / bfill :使用后一个值来填充缺失值
limit 填充的缺失值个数限制。应该不怎么用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
>>> df.fillna(0)
A B C D
0 0.0 2.0 0.0 0
1 3.0 4.0 0.0 1
2 0.0 0.0 0.0 5
3 0.0 3.0 0.0 4
>>> df.fillna(method='ffill')
A B C D
0 NaN 2.0 NaN 0
1 3.0 4.0 NaN 1
2 3.0 4.0 NaN 5
3 3.0 3.0 NaN 4
>>>df.fillna(method='bfill')
A B C D
0 3.0 2.0 NaN 0
1 3.0 4.0 NaN 1
2 NaN 3.0 NaN 5
3 NaN 3.0 NaN 4
|
csv操作
- 读csv不要索引
1
| df = pd.read_csv("filename.csv",encoding='utf-8',index_col=0)
|
- 写csv不要索引
1
| df.to_csv("xxx.csv",index=False)
|
- 删除有空值的行
1
| df1 = df.dropna(subset=['列名'])
|
- 先把带有时间的列转为date_time格式,再进行排序。
1
2
| df1['time'] = pd.to_datetime(df1['time'])
df1.sort_values('time', inplace=True)
|
inplace代表是否更改数据,默认是False,要保存结果的话需要inplace=True。
- 增加一列并赋值
- 插入列
1
2
| df1.insert(3, 'users number', df2['users number'])
//df.insert(插入到哪一列, '列名', another_df['需要被插入的那一列'])
|
- Pandas sample()用于从DataFrame中随机选择行和列。
1
| DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
|
参数
1
2
3
4
5
6
7
8
9
10
11
12
| n:这是一个可选参数, 由整数值组成, 并定义生成的随机行数。
frac:它也是一个可选参数, 由浮点值组成, 并返回浮点值*数据帧值的长度。不能与参数n一起使用。
replace:由布尔值组成。如果为true, 则返回带有替换的样本。替换的默认值为false。
权重:它也是一个可选参数, 由类似于str或ndarray的参数组成。默认值”无”将导致相等的概率加权。
如果正在通过系列赛;它将与索引上的目标对象对齐。在采样对象中找不到的权重索引值将被忽略, 而在采样对象中没有权重的索引值将被分配零权重。
如果在轴= 0时正在传递DataFrame, 则返回0。它将接受列的名称。
如果权重是系列;然后, 权重必须与被采样轴的长度相同。
如果权重不等于1;它将被标准化为1的总和。
权重列中的缺失值被视为零。
权重栏中不允许无穷大。
random_state:它也是一个可选参数, 由整数或numpy.random.RandomState组成。如果值为int, 则为随机数生成器或numpy RandomState对象设置种子。
axis:它也是由整数或字符串值组成的可选参数。 0或”行”和1或”列”。
|
- 通过.fillna()填充空值。
1
| inputs = inputs.fillna(inputs.mean())
|
pandas按列遍历Dataframe
- iterrows(): 按行遍历,将DataFrame的每一行迭代为(index, Series)对,可以通过row[name]对元素进行访问。
- itertuples(): 按行遍历,将DataFrame的每一行迭代为元祖,可以通过row[name]对元素进行访问,比iterrows()效率高。
- iteritems():按列遍历,将DataFrame的每一列迭代为(列名, Series)对,可以通过row[index]对元素进行访问。
示例数据
1
2
3
4
5
6
| import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11, 'c2':110}, {'c1':12, 'c2':123}]
df = pd.DataFrame(inp)
print(df)
|

按行遍历iterrows():
1
2
| for index, row in df.iterrows():
print(index)
|
row[‘name’]
1
2
3
|
for row in df.iterrows():
print(row['c1'], row['c2'])
|
按行遍历itertuples():
getattr(row, ‘name’)
1
2
| for row in df.itertuples():
print(getattr(row, 'c1'), getattr(row, 'c2'))
|

按列遍历iteritems():
1
2
3
4
| for index, row in df.iteritems():
print(index)
|
c1
c2
1
2
| for row in df.iteritems():
print(row[0], row[1], row[2])
|

numpy
axis理解
参考: https://zhuanlan.zhihu.com/p/31275071
简单来说就是:
- Axis就是数组层级
- 设axis=i,则Numpy沿着第i个下标变化的方向进行操作
reshape()
重新定义矩阵的形状
相当于pytorch中的view()
1
2
3
| import torch
v1 = torch.range(1,16)
v2 = v1.view(4,4)
|
参数使用-1,view中一个参数定为-1,代表动态调整这个维度上的元素个数,以保证元素的总数不变
1
2
3
4
5
| import torch
v1 = torch.range(1,16)
v2 = v1.view(-1,4)
|
np.r_ 和 np.c_
np.r_是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等。
np.c_是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| a = np.array([[1, 2, 3],[7,8,9]])
b=np.array([[4,5,6],[1,2,3]])
>>a
Out[4]:
array([[1, 2, 3],
[7, 8, 9]])
>>b
Out[5]:
array([[4, 5, 6],
[1, 2, 3]])
c=np.c_[a,b]
>>c
Out[7]:
array([[1, 2, 3, 4, 5, 6],
[7, 8, 9, 1, 2, 3]])
|
eye()
numpy.eye(N,M=None,k=0,dtype=<class ‘float’>,order=’C)
返回的是一个二维2的数组(N,M),对角线的地方为1,其余的地方为0.
参数介绍:
(1)N:int型,表示的是输出的行数
(2)M:int型,可选项,输出的列数,如果没有就默认为N
(3)k:int型,可选项,对角线的下标,默认为0表示的是主对角线,负数表示的是低对角,正数表示的是高对角。
(4)dtype:数据的类型,可选项,返回的数据的数据类型
(5)order:{‘C’,‘F’},可选项,也就是输出的数组的形式是按照C语言的行优先’C’,还是按照Fortran形式的列优先‘F’存储在内存中
1
2
3
4
5
6
7
8
9
10
11
12
13
| import numpy as np
a=np.eye(3)
print(a)
a=np.eye(4,k=1)
print(a)
a=np.eye(4,k=-1)
print(a)
a=np.eye(4,k=-3)
print(a)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]
[0. 0. 0. 0.]]
[[0. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[1. 0. 0. 0.]]
|
深度学习高级用法
将数组转化为 one-hot形式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import numpy as np
labels = np.array([[1],[2],[0],[1]])
print('label的大小:',labels.shape,'\n')
a=np.eye(3)[1]
print("如果对应的类别号是1,那么转成one-hot的形式",a,"\n")
a=np.eye(3)[2]
print("如果对应的类别号是2,那么转成one-hot的形式",a,"\n")
a=np.eye(3)[1,0]
print("1转成one-hot的数组的第一个数字是:",a,"\n")
a=np.eye(3)[[1,2,0,1]]
print("如果对应的类别号是1,2,0,1,那么转成one-hot的形式\n",a)
res=np.eye(3)[labels.reshape(-1)]
print("labels转成one-hot形式的结果:\n",res,"\n")
print("labels转化成one-hot后的大小:",res.shape)
|
结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| labels的大小: (4, 1)
如果对应的类别号是1,那么转成one-hot的形式 [0. 1. 0.]
如果对应的类别号是2,那么转成one-hot的形式 [0. 0. 1.]
1转成one-hot的数组的第一个数字是: 0.0
如果对应的类别号是1,2,0,1,那么转成one-hot的形式
[[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]]
labels转成one-hot形式的结果:
[[0. 1. 0.]
[0. 0. 1.]
[1. 0. 0.]
[0. 1. 0.]]
labels转化成one-hot后的大小: (4, 3)
label.reshape(-1)
--> array([1,2,0,1])变成了一维数组
|
identity()
与eye()的区别在于只能创建方阵
np.linalg.norm求范数
1
| x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import numpy as np
x = np.array([
[0, 3, 4],
[1, 6, 4]])
print "默认参数(矩阵整体元素平方和开根号,不保留矩阵二维特性):",np.linalg.norm(x)
print "矩阵整体元素平方和开根号,保留矩阵二维特性:",np.linalg.norm(x,keepdims=True)
print "矩阵每个行向量求向量的2范数:",np.linalg.norm(x,axis=1,keepdims=True)
print "矩阵每个列向量求向量的2范数:",np.linalg.norm(x,axis=0,keepdims=True)
print "矩阵1范数:",np.linalg.norm(x,ord=1,keepdims=True)
print "矩阵2范数:",np.linalg.norm(x,ord=2,keepdims=True)
print "矩阵∞范数:",np.linalg.norm(x,ord=np.inf,keepdims=True)
print "矩阵每个行向量求向量的1范数:",np.linalg.norm(x,ord=1,axis=1,keepdims=True)
|
squeeze()
作用:从数组的形状中删除单维度条目,即把shape中为1的维度去掉,对非单维的维度不起作用
np.squeeze(a, axis = None)
1
2
3
4
5
| 1)a表示输入的数组;
2)axis用于指定需要删除的维度,但是指定的维度必须为单维度,否则将会报错;
3)axis的取值可为None 或 int 或 tuple of ints, 可选。若axis为空,则删除所有单维度的条目;
4)返回值:数组
5) 不会修改原数组;
|
eg:
1
2
3
4
5
6
7
8
9
10
11
12
13
| import numpy as np
a = np.arange(10).reshape(1, 10)
# array([[0,1,2,3,4,5,6,7,8,9]])
a.shape
# (1,10)
b = np.squeeze(a)
# array([0,1,2,3,4,5,6,7,8,9])
b.shape
# (10,)
|
dot()
向量点积 和 多维矩阵乘法
切片
一维数组
通过冒号分隔切片参数 start:stop:step 来进行切片操作:
冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
注意1:
1
2
3
4
5
6
7
| import numpy as np
a = np.array([1,2,3,4,5,6,7,8])
>>> a[7:]
array([8])
>>> a[7]
8
|
注意2:
1
2
| >>> print(a[1:3])
[2 3]
|
二维数组
1
2
3
4
5
6
7
| import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
[[1 2 3]
[3 4 5]
[4 5 6]]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| >>> a[1]
array([3, 4, 5])
>>> a[1:]
array([[3, 4, 5],
[4, 5, 6]])
>>> a[:2]
array([[1, 2, 3],
[3, 4, 5]])
>>> a[1:2]
array([[3, 4, 5]])
>>> a[1,]
array([3, 4, 5])
>>> a[1:,]
array([[3, 4, 5],
[4, 5, 6]])
>>> a[:2,]
array([[1, 2, 3],
[3, 4, 5]])
>>> a[1:2,]
array([[3, 4, 5]])
|
总结:
这是numpy的切片操作,一般结构如num[a:b,c:d],分析时以逗号为分隔符,
逗号之前为要取的num行的下标范围(a到b-1),逗号之后为要取的num列的下标范围(c到d-1);
前面是行索引,后面是列索引。
如果是这种num[:b,c:d],a的值未指定,那么a为最小值0;
如果是这种num[a:,c:d],b的值未指定,那么b为最大值;c、d的情况同理可得。
所以重点就是看逗号,没逗号,就是看行了,冒号呢,就看成一维数组的形式啦。那上面逗号后面没有树,也就是不对列操作咯。
当然也可以这样:
1
2
3
| a[:2:1]
array([[1, 2, 3],
[3, 4, 5]])
|
首先没有逗号,那切片就是只看行了,这里的意思是,从0开始到2(2不算),间隔为1。
结合matplotlib画图
%matplotlib inline 可以在Ipython编译器里直接使用,功能是可以内嵌绘图,并且可以省略掉plt.show()这一步。
pyplot库
1
| import matplotlib.pyplot as plt
|
绘制直线
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import matplotlib.pyplot as plt
import numpy as np
xpoints = np.array([0, 6])
ypoints = np.array([0, 100])
plt.title("TITLE")
plt.xlabel("x - label")
plt.ylabel("y - label")
plt.plot(xpoints, ypoints)
plt.show()
|
plt.plot()函数是绘制二维函数的最基本函数
1
2
3
4
| >>> plot(x, y)
>>> plot(x, y, 'bo')
>>> plot(y)
>>> plot(y, 'r+')
|
绘制多图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
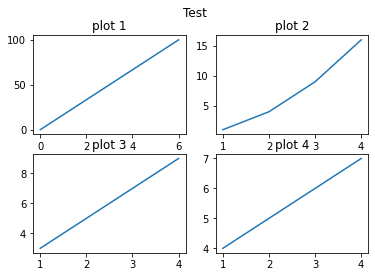
| import matplotlib.pyplot as plt
import numpy as np
x = np.array([0, 6])
y = np.array([0, 100])
plt.subplot(2, 2, 1)
plt.plot(x,y)
plt.title("plot 1")
x = np.array([1, 2, 3, 4])
y = np.array([1, 4, 9, 16])
plt.subplot(2, 2, 2)
plt.plot(x,y)
plt.title("plot 2")
x = np.array([1, 2, 3, 4])
y = np.array([3, 5, 7, 9])
plt.subplot(2, 2, 3)
plt.plot(x,y)
plt.title("plot 3")
x = np.array([1, 2, 3, 4])
y = np.array([4, 5, 6, 7])
plt.subplot(2, 2, 4)
plt.plot(x,y)
plt.title("plot 4")
plt.suptitle("Test")
plt.show()
|
注: plt.subplot(2,2,1) <=> plt.subplot(221)
散点图
1
2
3
4
5
6
7
8
| import matplotlib.pyplot as plt
import numpy as np
x = np.array([1, 2, 3, 4, 5, 6, 7, 8])
y = np.array([1, 4, 9, 16, 7, 11, 23, 18])
sizes = np.array([20,50,100,200,500,1000,60,90])
plt.scatter(x, y, s=sizes)
plt.show()
|
柱形图
1
2
3
4
5
6
7
8
9
10
| import matplotlib.pyplot as plt
import numpy as np
x = np.array(["num-1", "num-2", "num-3", "num-4"])
y = np.array([12, 22, 6, 18])
plt.bar(x,y)
plt.show()
|
饼图
1
2
3
4
5
6
7
8
9
10
11
| import matplotlib.pyplot as plt
import numpy as np
y = np.array([35, 25, 25, 15])
plt.pie(y,
labels=['A','B','C','D'],
colors=["#d5695d", "#5d8ca8", "#65a479", "#a564c9"],
)
plt.title("Pie Test")
plt.show()
|
三维图
最基本的三维图是线图与散点图,可以用ax.plot3D和ax.scatter3D函数来创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
from mpl_toolkits import mplot3d
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
ax = plt.axes(projection='3d')
zline = np.linspace(0, 15, 1000)
xline = np.sin(zline)
yline = np.cos(zline)
ax.plot3D(xline, yline, zline, 'gray')
zdata = 15 * np.random.random(100)
xdata = np.sin(zdata) + 0.1 * np.random.randn(100)
ydata = np.cos(zdata) + 0.1 * np.random.randn(100)
ax.scatter3D(xdata, ydata, zdata, c=zdata, cmap='Greens')
|
热图
imshow()
1
2
3
4
5
| import matplotlib.pyplot as plt
X = [[1, 2], [3, 4], [5, 6]]
plt.imshow(X)
plt.colorbar()
plt.show()
|

博客:https://blog.csdn.net/qq_21763381/article/details/100169288

