
位置编码
位置编码
起源-Transformer
transformer提出了经典的Sinusoidal位置编码,然后各种位置编码被陆续提出,也产生了一些变体Transformer如(Reformer)
思考一:位置编码是干嘛,什么是好的位置编码方案
位置编码是表示字句时序位置的编码,因为Transformer这种纯靠attention的模型,无法天然的获取位置信息(即改变attention的内部顺序得到的结果没有变)
好的位置编码:
- 对于给定的位置,它的位置编码是唯一的 (绝对和相对按道理都应该这样)
- 不同长度的句子之间,任何两个时间步之间的距离应该尽量一致
- 模型是很容易泛化到更长句子的 (最近的Longtext研究给了一些泛化方案)
但是具体来说还需要考虑计算复杂度,具体下游任务的实际实验效果
疑惑一: 为什么position encoding就直接加到embedding向量上了
根据网上的理解,embedding本质就是onehot进行全连接,所以coding之后相加其实等价于coding之前torch.cat之后再进行一个大的全连接。所以相加相当于一个特征的融合,相加也符合向量空间关系的一种折中,Bert coding的时候相加也可以相同理解
那为什么不能是向量相乘呢(后续也有相关工作)
绝对位置编码
三角式
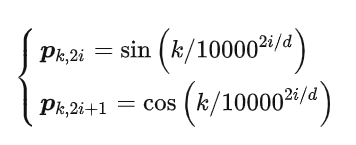
其中 pk,2i, pk,2i+1 分别是位置 k 的编码向量的第 2i,2i+1 个分量,d 是位置向量的维度。
是绝对位置编码,但含有相对位置信息,推导可以从泰勒展开理解,但仅限二维,所以可解释性差
递归式
论文:Learning to Encode Position for Transformer with Continuous Dynamical Model
思想就是通过 RNN 结构来学习一种编码方案,外推性较好,但牺牲了并行性,可能会带来速度瓶颈
相乘式
博客:https://zhuanlan.zhihu.com/p/183234823
RoPE旋转位置编码
也是绝对位置编码。
二维形式: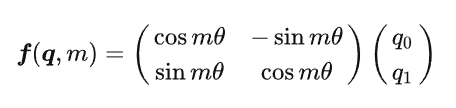
根据矩阵乘法的几何意义可以知道,此时实际上代表着query向量的旋转,所以取名旋转位置编码。
动机:原来的Sinusoidal编码不够好
作者苏剑林是从向量的内积表示两个向量的位置关系出发,通过复数表示(两个复向量的内积为复向量*复向量的共轭),推导出了这样一个旋转位置编码,更有可解释性,从预训练模型 RoFormer 的结果来看,RoPE 具有良好的外推性,应用到 Transformer 中体现出较好的处理长文本的能力。且能作用于线性attention(Transformer的attention为二阶复杂度),因为编码矩阵是正交矩阵且直接作用于query和key,不改变向量模长。
偶数多维:

由于$R_{n-m}$是正交矩阵,不改变向量模长,所以应该不会改变模型的稳定性
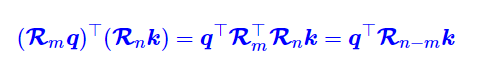
苏剑林还想到将这样一个稀疏矩阵乘积化成
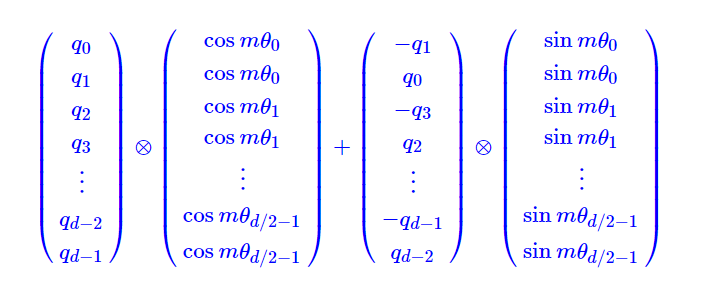
既降低计算的复杂度,使RoPE可以视为乘性位置编码的变体
最近几天国外网友推出的NTK-Aware Scaled RoPE,使苏剑林提出了:从 β 进制编码的角度理解 RoPE,放在后面讲
一些使用RoPE的模型(ReFormer(苏剑林自己开源的)、GlobalPoint)
相对位置编码
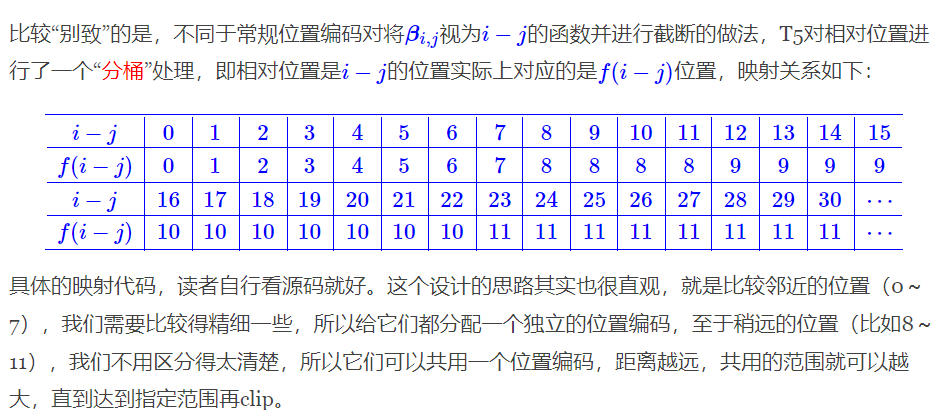
经典式

只需要有限个位置编码,就可以表达出任意长度的相对位置(因为进行了截断)
XLNET式
《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
位置编码:
$\boldsymbol{q}{i} \boldsymbol{k}{j}^{\top}=\boldsymbol{x}{i} \boldsymbol{W}{Q} \boldsymbol{W}{K}^{\top} \boldsymbol{x}{j}^{\top}+\boldsymbol{x}{i} \boldsymbol{W}{Q} \boldsymbol{W}{K}^{\top} \boldsymbol{p}{j}^{\top}+\boldsymbol{p}{i} \boldsymbol{W}{Q} \boldsymbol{W}{K}^{\top} \boldsymbol{x}{j}^{\top}+\boldsymbol{p}{i} \boldsymbol{W}{Q} \boldsymbol{W}{K}^{\top} \boldsymbol{p}{j}^{\top} —(*)$
最终:
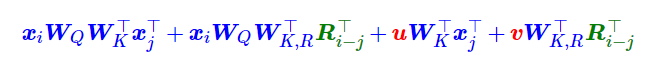

相对位置矩阵只加到 attention 矩阵上,不加到 $v_j$ 上去了,后续的工作也都如此
T5 式
《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》
*式可以理解为“输入-输入”、“输入-位置”、“位置-输入”、“位置-位置”四项注意力的组合,如果我们认为输入信息与位置信息应该是独立(解耦)的,那么它们就不应该有过多的交互,所以“输入-位置”、“位置-输入”两项 Attention 可以删掉。
而 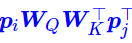 实际上只是一个只依赖于(i, j)的标量,我们可以直接将它作为参数训练出来,即简化为
实际上只是一个只依赖于(i, j)的标量,我们可以直接将它作为参数训练出来,即简化为 
说白了,它仅仅是在 Attention 矩阵的基础上加一个可训练的偏置项而已,而跟 XLNET 式一样,在 $v_j$ 上的位置偏置则直接被去掉了
包含同样的思想的还有微软在ICLR 2021的论文《Rethinking Positional Encoding in Language Pre-training》中提出的TUPE位置编码
TUPE位置编码中还通过重置与[CLS]相关的位置相关性来解除[CLS]
DoBERTa 式
DeBERTa 和 T5 刚刚相反,它扔掉了第 4 项,保留第 2、3 项并且替换为相对位置编码

语录:==科研就是枚举所有排列组合看哪个更优==
LongText最新进展:
- baseline 直接外推
- SuperHOT LoRA 线性内插+微调 同时还有Meta的《Extending Context Window of Large Language Models via Positional Interpolation》
首先是进制思想
其次线性内插其实简单来说就是将2000以内压缩到1000以内
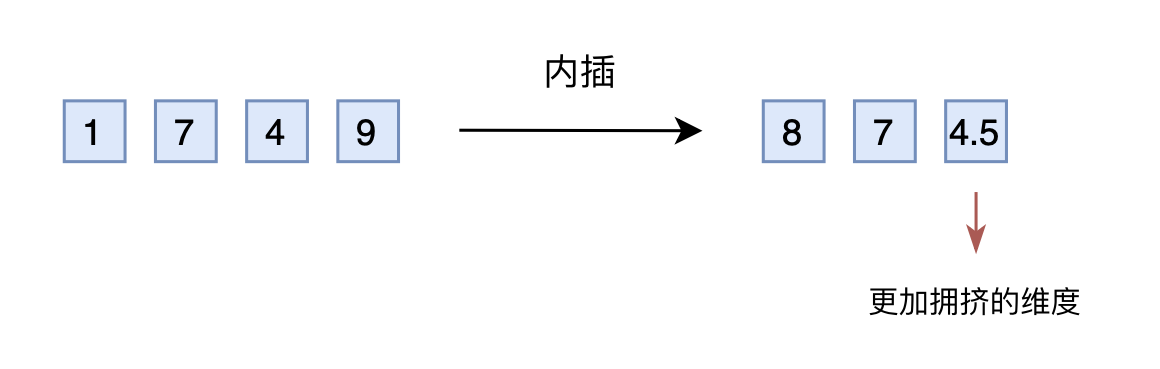
原本模型已经学会了875>874, 现在泛化一个874.5>874应该不会太难
- NBCE (Naive Bayes-based Context Extension) https://kexue.fm/archives/9617 (之前苏剑林根据朴素贝叶斯提出的一个东西,他测试不微调就可以扩展Context长度)
- NTK-Aware Scaled RoPE (不微调就很好,微调了可能更好) Transformer 升级之路:10、RoPE 是一种β进制编码
一方面可以从进制方面理解,另一方面可以从高频外推,低频内插理解

这个扩增方案就能解释直接外推方案就是啥也不改,内插方案就是将n换成n/k。
进制转换,就是要扩大k倍表示范围,那么原本的β进制至少要扩大成$β(k^{2/d})$进制或者等价地原来的底数10000换成10000k
这其实就是NTK-Aware Scaled RoPE (苏剑林的推导)
提出者的推导:高频外推、低频内插
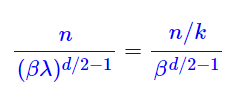
苏剑林的实验中还发现NTK-RoPE在“重复”外推上比“不重复”外推效果明显好,表明这样修改之后是保留了全局依赖,而不是单纯将注意力局部化
- Myth of Context Length : Stanford & UC Berkeley & Samaya AI
- 扩展上下文的模型不一定更擅长利用其输入上下文
eg: longchat在140个键值设置中,longchat是一个显著的异常值;当相关信息在输入上下文的开头时, 它倾向于生成用于检索键的代码,而不是输出值本身。
- 与其基准模型(即在指令微调之前)MPT30B相比,MPT-30B-Instruct在多文档问答中的性能表现进行了对比。这两个模型都具有一个呈U型的性能曲线,当相关信息出现在输入上下文的开头 或结尾时,性能显著提高,这表明指令调优过程本 身不一定是造成这些性能趋势的原因
- 查询query和数据data的顺序对于decoder-only模型?(decoder-only模型在每个时间步只能关注先前标记的方式来处理)
Query-Aware Contextualization显著提高key-value retrieval task, 对多文档问题提升不大(放在开头稍好)
结论: 有监督 的指令微调数据中,任务规范和/或指令通常 放置在输入上下文的开头,这可能导致经过指 令微调的语言模型更重视输入上下文的开头部 分
- 根据下游任务权衡上游模型。提供更多信息给经过训练的 指令型语言模型,可能有助于提高下游任务的 性能,但也会增加模型需要处理的内容量。
==只做了实验探究,没有给出合理的解释,只给出了一个人类心理学现象作为类比==
6. softmax_1:https://www.evanmiller.org/attention-is-off-by-one.html?continueFlag=5d0e431f4edf1d8cccea47871e82fbc4
思考二:
- 线性内插当处理范围更大时,内插方案的维度(先是个位,后十位)会压缩得更拥挤,每个维度的极限密度(达到性能瓶颈)是多少
这应该取决于具体的计算资源、内存限制和线性内插算法的效率
在具体的下游任务上评估线性内插压缩的程度的影响,不同的下游任务可能是不是选不同的k
为什么在transformer这类模型中,长文本时同样更容易注意两端文本
transformer的改进(一直都在进行的工作)
