
语言模型
Language model-系列:
夏季创新课报告-语言模型
学号:2021112905 姓名:徐浩铭
从智能体出发
- 介绍了chatGPT的背景和作用。chatGPT是OpenAI公司开发的对话机器人,标志着自然语言处理技术取得突破,从弱AI向强AI转变。
- 从语言模型的角度分析chatGPT。chatGPT的核心是大型语言模型,可以处理自然语言的远距离依赖关系,进行语义计算,具备多任务处理能力。
- 从知识的角度分析chatGPT。chatGPT实现了知识的统一,是大知识和富知识,改变了人类的知识获取方式。
- 分析了chatGPT对互联网内容生成、社交媒体、各行各业的影响。
- 探讨了人工智能产业的发展趋势。chatGPT带来新的chatGPT+X模式,形成新的产业集群和创新网络。
==智能体才是未来==
n-gram
介绍了语言现象、语料库、如何从语料库中学习语言知识的基本思路。
介绍了语言模型n-gram的相关内容:
(1) 定义了语言模型的两个作用: (a) 计算一个词序列s出现的概率p(s),判断s是否是一个合法的语言现象。 (b) 在给定上下文context的条件下,预测下一个词w的概率p(w|context)。
(2) 介绍了利用语料库训练语言模型n-gram的过程:
(a) 对语料库中的文本进行分词,获得词序列。
(b) 统计词频,得到每个词w的出现次数c(w)。
(c) 统计bigram频率,得到每个词对(w1,w2)的出现次数c(w1,w2)。
(d) 统计trigram频率,得到每个词组(w1,w2,w3)的出现次数c(w1,w2,w3)。 (e) 将这些统计结果保存为unigram、bigram、trigram模型。
(3) 介绍了如何利用n-gram模型计算句子概率,以及平滑处理方法。 (4) 介绍了n-gram模型的评价方法和下一词预测方法。 (5) 介绍了困惑度可以评价n-gram模型的效果,分析了n-gram模型的优缺点。
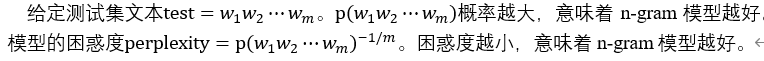
(6)总结了n-gram模型的优缺点: (a) 优点:无监督训练,利用近义词相关性。 (b) 缺点:n限制在3以下,只用了短距离相关性。
介绍了词典tokenize的两种方法:中文分词和BPE英文子词切分法。
BPE英文字词分法:https://zhuanlan.zhihu.com/p/383650769
结尾部分,讨论了语言模型的why、what和how三个问题。 why:阐述了学习语言模型的意义在于服务于智能体。 what:概述了语言模型的发展历程。 how:分析了语言模型学习资料的局限性,需要多方查阅。
词向量
导言部分提出语言模型的三大任务:学习词语义、文本理解和文本生成。
介绍了表示词语义的两种方法:
(1) 建立知识库的方法获取词语义, 类似字典,面临语料覆盖有限、无法判断上下文词义的问题。
(2) 统计语言模型n-gram,对词进行了符号表示。

(3) one-hot编码:给定一个词典V,将每个词表示为一个二进制向量。**向量的维度为|V|**,它采用词表中每个词的索引作为二进制编码的位置,只有该位置上取值为1,其他位置的取值都为0。这种词的编码,称为one-hot编码。
one-hot向量是词的一种符号表示,没有表示出词的语义。
one-hot编码是个高维、稀疏的向量。向量维度是词典的大小。
one-hot向量是正交的,不能计算两个词之间的相似度。
(4) 利用上下文学习词向量的分布式表示方法(上下文相似的词,有着相似的语义)。
介绍了词编码的两种表示:
(1) One-hot 高维稀疏的离散表示,无法计算词义相关性。
(2) ==词向量==低维稠密的连续实数表示,可以表示词义。详细介绍了Bengio等人提出的神经网络语言模型NNLM:
(1) 模型结构:输入层、词向量层、隐层、输出层。详述了每个层的计算公式。
(2) 模型参数:词向量矩阵E,隐层矩阵W、偏置b,输出层矩阵W、偏置b。
(3) 目标函数设计采用最大对数似然估计。
(4) 通过学习词向量矩阵E获得词向量。
介绍了Mikolov的CBOW模型:
(1) 模型结构:输入层、词向量层、隐层、输出层。详述了每个层的计算公式。
(2) 模型参数:上下文词向量矩阵E,输出词向量矩阵E’。
(3) 目标函数采用对数似然估计。
(4) 通过输入词上下文,学习输出词的词向量。
每个词的词向量是一个低维稠密的实数向量,学习了词的语义表示。
每个词被映射到一个固定维度的向量空间。语义相近的词在空间中的距离较近。通过计算两个词向量之间的相似度,也学习到两个词之间的语义相关性。
神经网络
- 神经网络的思想从神经元得来
- 激活函数、前馈网络、文本分类、情感分析
RNN
介绍了循环神经网络语言模型RNN LM:
(1) RNN模型结构包括输入层、隐层和输出层。隐层保存历史信息。
(2) RNN语言模型的输入为完整的上下文序列,输出为下一个词。克服了固定窗口长度的限制。
(3) 详细介绍了RNN语言模型的输入层、隐层和输出层的计算公式。
(4) RNN语言模型可以用来文本生成。
分析了RNN的不同任务:
(1) one-one:多层感知机MLP。
(2) one-many:图像标题生成。
(3) many-one:文本生成、情感分类。
(4) many-many:序列标注、seq2seq编解码
(5) Encoder-Decoder:机器翻译。
介绍了RNN的改进模型LSTM:

(1) LSTM在RNN基础上增加了记忆单元。
(2) LSTM单元详细介绍了输入、输出和各个门的计算。
(3) LSTM引入了门控机制解决了RNN的梯度问题。
RNN的本质分析:
(1) RNN是一个序列模型,可以处理变长序列,编码历史序列信息。
(2) RNN通过隐层保存历史,实现序列间的依赖学习。
(3) RNN是一个通用的序列学习框架,可用于多种不同的序列任务。
(4) RNN的改进模型LSTM增强了 RNN 在较长序列上的记忆能力。
attention+Transformer
编码器-解码器结构的机器翻译模型(seq2seq)存在的问题:
(1)Encoder(RNN)生成的上下文向量,缺乏远距离的语言依赖关系。(2)对Decoder的当前状态所对应的语言依赖关系,也缺乏指导。
注意力机制的原理:计算查询和键值之间的相关性,对值进行加权求和作为输出。可以建模远距离依赖关系。
eg: TextRNN+attention进行文本分类任务
自注意力机制的本质:利用上下文中的词为目标词编码,计算目标词与上下文词的相关性作为权重,上下文词的词向量作为特征值,加权求和作为目标词的表示。
掩码自注意力机制:防止目标词看到后面的词,只利用前面的上下文进行编码。
多头自注意力机制:使用多个不同的键、值、查询投影,获得多个子空间的表示,提高模型表达能力。
Transformer的组成:输入模块、Encoder模块、Decoder模块、输出模块。核心是stacked的Encoder和Decoder中的多头自注意力机制和前馈全连接网络。
Transformer的预训练:最大化语料概率;微调:最大化人工标注语料的概率。
典型的预训练语言模型GPT和BERT的区别:前者自回归预测下一个词,后者掩码预测被遮蔽的词。
Transformer利用注意力机制有效建模全局依赖关系,是当前自然语言处理中主流的模型结构。
